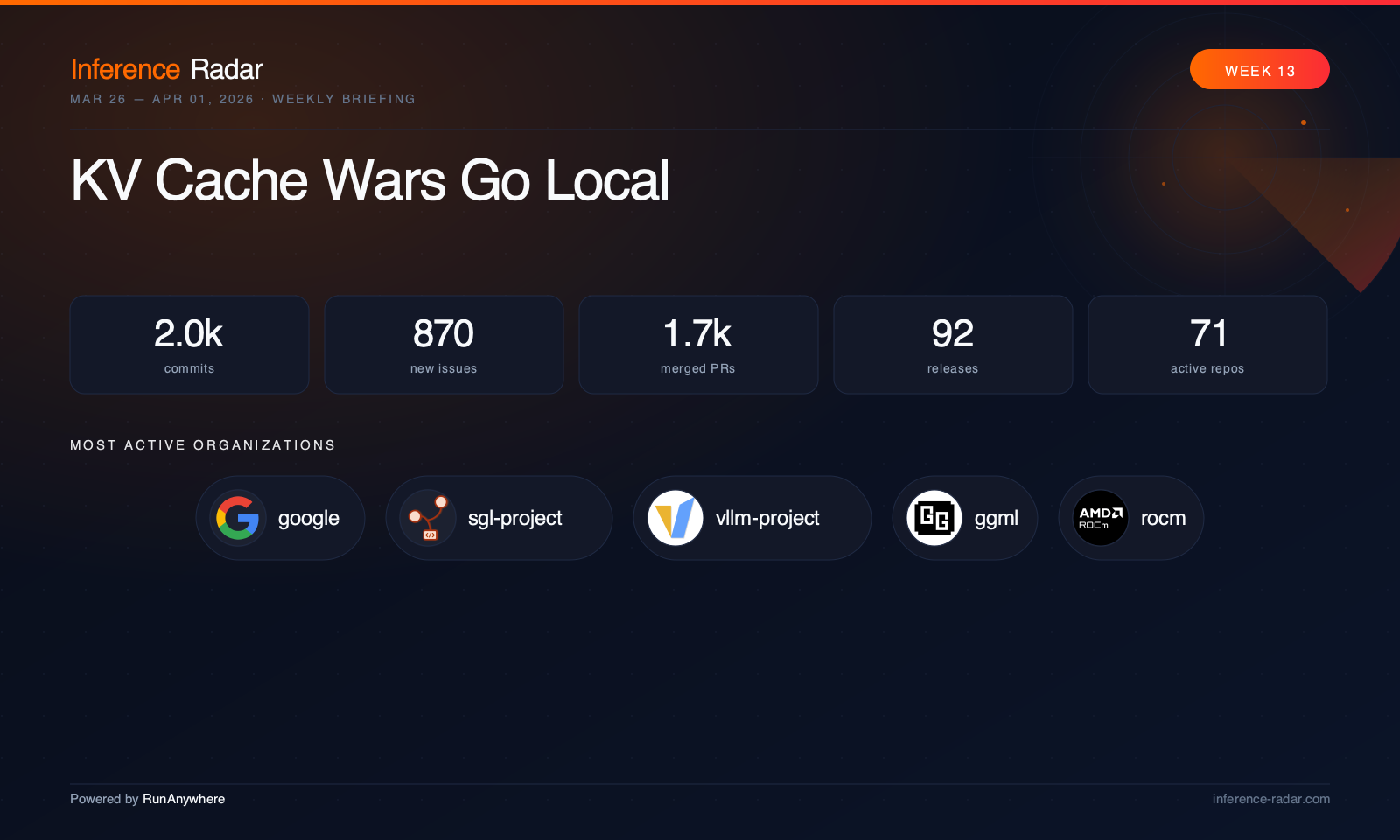

TL;DR
- KV cache becomes the new battleground: vLLM, SGLang, and Google’s TurboQuant push all pointed in the same direction this week: memory movement and cache compression are now central to inference economics, not an implementation detail.1
- Apple Silicon stops being a side quest: Ollama, SGLang, and omlx all expanded MLX- and Apple-focused paths, turning the Mac from a developer convenience into a serious local inference target.2
- Edge speech stacks are maturing fast: ExecuTorch, sherpa-onnx, and FluidAudio all shipped meaningful speech and streaming work, suggesting on-device audio is becoming one of open inference’s most production-ready categories.5
- Serving engines are preparing for heterogeneous clusters: ai-dynamo, vLLM, and ONNX Runtime all invested in engine-agnostic APIs, plugin backends, and disaggregated execution patterns that matter more as inference spreads across mixed hardware.1
- Ultra-low-bit inference moves from experiment to distribution: PrismML’s Bonsai model, llama.cpp, and community demand around TurboQuant-style compression show that “how small can we make it” is now a product question, not just a research one.10
This Week in Inference
The biggest market signal this week was that inference optimization is no longer splitting neatly into “cloud” and “local” tracks. Google’s TurboQuant claims around KV-cache compression reframed the week’s conversation: once model weights are already quantized, the next cost center is the live memory footprint of serving long contexts and many concurrent users, especially in attention-heavy workloads. That same pressure showed up in open-source code across vLLM, SGLang, and OpenVINO, all of which spent meaningful effort on cache behavior, attention correctness, or disaggregated serving internals.1
On the model side, the most interesting release was PrismML’s Bonsai 8B, distributed in a 1-bit form and aimed squarely at constrained local deployment via GGUF-compatible tooling, as noted in the market briefing’s announcement roundup.12 Even where the biggest model launches sat just outside the strict window, the adjacent context mattered: Google’s Gemma family and NVIDIA’s optimization push across RTX, DGX Spark, and Jetson reinforced the new open-model playbook, where permissive licensing and immediate downstream optimization matter as much as benchmark quality, per Ars Technica and NVIDIA’s Gemma optimization post.13
Hardware news fit the same pattern. ASUS’s USB-attached accelerator, built around Hailo silicon, is notable less for raw TOPS than for what it says about deployment shape: inference hardware is becoming attachable, modular, and consumer-adjacent, not just embedded or datacenter-only, according to the ASUS announcement.15 Meanwhile, the software stack kept moving toward heterogeneity. ExecuTorch, ONNX Runtime, ai-dynamo, and SGLang all spent the week making it easier to target mixed backends, plugin execution providers, or disaggregated serving topologies.2 The industry’s center of gravity is shifting from “pick one runtime” to “compose a serving path across many runtimes.”
Top Stories
vLLM and SGLang turn KV cache into infrastructure
The most important code trend this week was the amount of serious systems work landing around KV movement, quantization, and disaggregation in vLLM and SGLang.1 vLLM pushed per-token-head KV-cache quantization and broader executor redesign work, while SGLang overhauled disaggregated KV transfer with GPU staging and ring allocation. Together, they make clear that the next generation of serving performance will come less from raw matmul speed and more from how intelligently engines move, compress, and share state across requests and machines.
Ollama makes Apple-first local inference feel real
Ollama spent the week stabilizing its MLX-powered Apple Silicon path with tokenizer compatibility fixes, KV-cache cleanup, and model-specific work for Qwen-family behavior.3 That matters because Apple support is no longer just about “it runs on a Mac”; it’s about whether local inference on Apple hardware can handle real workloads with tool use, vision, and long-lived sessions. The parallel arrival of MLX backend work in SGLang and multimodal/audio expansion in omlx suggests the broader ecosystem now sees Apple Silicon as a first-class deployment tier.2
ExecuTorch pushes on-device speech from demo to product surface
ExecuTorch shipped one of the week’s most consequential edge-runtime updates, centered on real-time speech and streaming inference.5 Unlimited-style streaming via ring-buffer KV behavior, streaming VAD support, and broader backend portability across Vulkan, OpenVINO, Core ML, Qualcomm, Arm, and embedded targets move the project closer to being a practical runtime for shipping multimodal apps, not just benchmarking them. In the same week, sherpa-onnx and FluidAudio expanded cross-platform ASR support, making speech the clearest category where edge inference is becoming operationally mature.6
ONNX Runtime bets on plugin backends as the next abstraction layer
ONNX Runtime had a strategically important week even without a flashy model headline.9 The project expanded plugin execution-provider APIs, added core CUDA plugin support, and kept pushing WebGPU and heterogeneous backend correctness. That matters because the future of inference infrastructure increasingly depends on being able to slot in specialized accelerators and vendor runtimes without rewriting the whole serving layer.
ai-dynamo quietly builds the control plane for mixed-engine serving
ai-dynamo did not ship a release, but it may have had one of the most important architectural weeks in the stack.8 The project expanded multimodal support, unified internal request representations across engines, and kept hardening routing, planner isolation, and observability. If vLLM and SGLang are competing to be the best engine, Dynamo is increasingly positioning itself as the layer that lets operators use several of them at once.
Deeper Dive
Everything below is for readers who want the full picture. Feel free to scroll.
Code Changes by Category
Cloud & Datacenter Serving
vLLM had one of the heaviest weeks in the ecosystem, and the throughline was clear: serving architecture is being rebuilt around memory efficiency and heterogeneous execution.1 The headline changes included per-token-head INT8/FP8 KV-cache quantization, MXFP8 work in Marlin GEMM and MoE paths, and a major executor redesign through RayExecutorV2, all visible in the project’s weekly activity and release stream.16 There was also meaningful model/runtime expansion, including Phi reasoning-vision support, DFlash speculative decoding, CPU attention head-size expansion, and a steady stream of correctness fixes around imports, video limits, and scheduler behavior (vLLM repo).1
SGLang matched that intensity but with a slightly different emphasis: disaggregation, multi-accelerator portability, and structured serving internals.2 The biggest systems change was the KV transfer overhaul for disaggregated serving, using GPU staging buffers and a dynamic ring allocator, while roadmap discussions around distributed KV cache, prefill/decode separation, and context parallelism showed where the maintainers think the architecture is headed (SGLang repo).2 The project also broadened support across AMD, Blackwell, NPU, MUSA, and MLX, while tightening multimodal correctness and adding observability like MFU Prometheus metrics.17
ai-dynamo continued to look like the orchestration layer for a multi-engine world.8 The most important work was not a single feature but a set of connective tissues: a unified internal request representation spanning vLLM, SGLang, TensorRT-LLM, frontend, router, and planner paths; initial audio and TTS support in the vLLM-omni backend; and stronger planner, routing, and replay infrastructure (ai-dynamo repo).8 The project also kept broadening hardware coverage with Intel XPU deployment templates and GPUDirect support, which fits the larger trend toward heterogeneous serving topologies.
ONNX Runtime spent the week on extensibility rather than end-user features.9 Plugin execution-provider APIs matured with profiling, schema access, and sync support, while a substantial CUDA Plugin EP implementation landed in parallel with WebGPU operator and performance work (ONNX Runtime repo).9 The practical implication is that ONNX Runtime is leaning harder into being the neutral substrate for many accelerators rather than just a monolithic runtime.
OpenVINO and openvino.genai had a strong week around attention correctness, NPU/GPU backend expansion, and benchmarking plumbing.11 SDPA fixes in core OpenVINO and Linear State support in GenAI matter because they touch the exact serving internals that increasingly dominate long-context and speculative workloads (OpenVINO repo, OpenVINO GenAI repo).11 The GenAI side also improved LoRA and video evaluation workflows, VLM chat benchmarking, and in-process memory monitoring.
Triton Inference Server had a quieter week, with a release but little detailed repo-level context in the supplied summaries (release page).20 DeepSpeed also shipped a release, but the provided data did not include enough repo-level detail to responsibly elevate it into the week’s main narrative (DeepSpeed repo).21
Local LLM Runtimes
Ollama was the most important local-runtime story of the week.3 The project’s MLX path got a serious stabilization pass: SentencePiece-style BPE compatibility, BOS-token handling, vision capability detection, and a long list of mlxrunner KV-cache fixes around leaks, eviction, snapshots, and state handling (Ollama repo).3 Just as important, Ollama kept improving model-specific behavior for Qwen-family models and tool-call parsing, which is what turns a local runtime from a benchmark toy into something people can actually build on.
llama.cpp had a massive release count at the org level and remains the reference point for portability, though the supplied summaries did not include a detailed repo narrative for the week’s code changes.10 The market briefing’s note that llama.cpp added 1-bit weight-format support is strategically important because it complements the rise of ultra-low-bit model distribution and GGUF packaging, even if the repo-level details weren’t included here (llama.cpp repo).10
omlx had one of the most interesting product weeks in local inference.4 Audio became a first-class capability with STT, TTS, and STS support via mlx-audio, while the app also expanded MCP workflows, multimodal/VLM support, constrained decoding, and enhanced quantization for large MoE models (omlx repo).4 The pattern here is notable: local runtimes are no longer just text chat shells; they are becoming integrated desktop inference environments with tools, voice, vision, and packaging complexity to match.
Open WebUI had a lighter code week than its issue volume suggests, but the work that landed was useful: startup reliability fixes, streaming/rendering performance improvements, config support, and UI memory-leak cleanup (Open WebUI repo).22 The issue queue tells the bigger story: tool-calling regressions, prompt-form breakage, and install/startup reliability remain the pressure points as local AI frontends become more application-like.
Other local stacks were quieter or lacked enough detail for strong editorial treatment. text-generation-webui had modest direct commit activity but no major release or clear thematic push in the supplied data.23 LocalAI showed strong aggregate activity, but without repo-level detail it’s better treated as a momentum signal than a headline.24
Apple Silicon & MLX Ecosystem
Apple Silicon was one of the week’s clearest cross-repo themes. Ollama made MLX stability a top priority, SGLang merged native MLX backend support, and omlx built an entire audio-and-multimodal product layer on top of the MLX stack (Ollama repo, SGLang repo, omlx repo).2 That combination matters more than any one release: it means Apple hardware is now being targeted by both serious serving engines and consumer-facing local apps.
uzu-swift shipped a substantial Swift SDK refresh, the most concrete first-party Apple-platform release in the supplied summaries.26 The exact feature-level details were sparse, but the size of the release commit suggests meaningful SDK and packaging movement for native Swift consumers.
The community side of the MLX ecosystem also mattered. A notable request in mlx-examples asked for Whisper flash attention and batched decoding with large speedup claims, which is a good proxy for where users want the stack to go next: not just compatibility, but serious performance engineering for speech workloads.27
Mobile & Edge Frameworks
ExecuTorch was the week’s most important mobile and edge framework story.5 The release centered on real-time speech and streaming inference, with Voxtral-style ring-buffer KV behavior and streaming Silero VAD support, but the broader significance was backend breadth: Vulkan, OpenVINO, Core ML, Qualcomm, Arm, NXP, CUDA, and MCU-related work all moved in the same week.28 That’s what a serious edge runtime looks like in 2026: not one backend, but many.
sherpa-onnx had a focused and impressive week around Qwen3-ASR support across nearly every language binding, plus hotword biasing and source-separation APIs (sherpa-onnx repo, ).29 It continues to stand out as one of the few projects that treats cross-platform speech deployment as a first-class product problem rather than a side effect of a core runtime.
FluidAudio had a release-heavy week and is quickly becoming one of the more interesting on-device speech stacks.7 The project reorganized its ASR architecture, added a streaming engine protocol, expanded model support, improved custom-vocabulary workflows, and tightened Swift concurrency/runtime correctness (FluidAudio repo, ).30 The pace of releases suggests a tight loop between architecture cleanup and user-facing capability expansion.
RunAnywhere SDKs focused on the less glamorous but essential side of edge inference: packaging.31 JNI symbol fixes, duplicate libc++_shared.so resolution, document picker dependency cleanup, and Flutter Android UI fixes all reduce the friction of embedding native inference into mobile apps (repo).31 The same theme showed up in user reports from Nexa SDK and RCLI: deployment reliability is still the biggest blocker for edge adoption.32
Compilers, Runtimes & Graph Engines
ONNX Runtime belongs here as much as in serving because its plugin EP work is really about runtime architecture.9 The project also kept pushing WebGPU performance and standards compliance, which matters as browser and client-side inference become more serious deployment targets (repo).9
OpenVINO continued to improve graph correctness and backend coverage, especially around SDPA, NPU FlashAttentionTile support, GPU kernels, and frontend operator support (repo).11 OpenVINO GenAI complemented that with benchmarking and pipeline-level work that makes those graph/runtime improvements visible to end users (repo).18
The supplied data did not include enough detailed activity for TVM, XNNPACK, or ONNX core repos to feature them prominently this week.34
Models, Quantization & Optimization
The market briefing’s biggest optimization story was Google’s TurboQuant, which claimed major KV-cache memory reduction and attention speedups via PolarQuant and QJL-style compression, as summarized in TechRadar.36 Whether the exact numbers hold up is almost secondary; the important part is that KV compression is now being discussed as a production lever.
That theme echoed in open-source demand. vLLM, Ollama, and OpenVINO all had visible community interest in TurboQuant-style KV compression or related memory-efficiency work.37 This is how a research idea becomes infrastructure: first papers, then issues, then PRs, then release notes.
On the model-distribution side, the 1-bit PrismML Bonsai release from the market briefing matters because it pairs with runtime-side support in llama.cpp.10 The combination suggests ultra-low-bit deployment is moving from “community conversion” to “officially distributed artifact,” which is a much bigger shift for the local ecosystem.
Hugging Face Diffusers had a quieter inference-specific week than the serving engines, but still contributed useful work around training support, quantization config cleanup, and correctness fixes for newer model families and workflows (repo).40 It was more of a maintenance-and-enablement week than a headline one.
Other Notable Changes
ROCm ATOM and aiter deserve special mention because they sit at the boundary between kernels, serving, and benchmarking.41 ATOM expanded its benchmarking dashboards, validation flows, and model compatibility, while aiter carried heavy operator refactors, GEMM tuning, and serving-path fixes (ATOM repo, aiter repo).41 Together they show AMD’s open inference stack becoming more measurable and more production-minded.
The hardware side of edge inference also got a useful market signal from ASUS’s USB accelerator announcement, which reinforces that attachable inference hardware is becoming part of the deployment conversation, not just integrated NPUs or datacenter GPUs (ASUS press release).15
Community Pulse
The loudest community theme this week was deployment friction. In local and edge stacks, users kept surfacing the same class of problems: model download failures in RCLI, NPU plugin loading failures on Snapdragon X Elite in Nexa SDK, and packaging or startup regressions in Open WebUI.32 That’s a sign of adoption, but also a reminder that the bottleneck has shifted from “can it run” to “can normal developers ship it.”
The second major theme was memory efficiency. TurboQuant-style KV compression requests appeared across vLLM, Ollama, and OpenVINO.37 When three very different communities ask for the same optimization in the same week, it usually means the problem is real.
Speech and streaming also had unusually healthy community energy. sherpa-onnx, FluidAudio, and mlx-examples all showed users pushing for better real-time behavior, better quality, or better performance.27 That’s a good sign for the category: people are no longer just asking whether on-device speech is possible.
Worth Watching
First, watch KV-cache work across the stack. The next few weeks are likely to bring more concrete implementations of compression, sharing, and disaggregation in vLLM, SGLang, and adjacent runtimes.1 This is the most important systems trend in inference right now.
Second, watch Apple Silicon. The combination of Ollama, SGLang, omlx, and uzu-swift suggests the ecosystem is converging on a more serious Apple-native stack.2 If MLX performance and packaging keep improving, the Mac may become the default “prosumer inference box.”
Third, watch speech as the edge category that gets there first. ExecuTorch, sherpa-onnx, and FluidAudio all moved fast this week, and speech has the right mix of latency sensitivity, privacy value, and manageable model size to become the proving ground for on-device AI.5
Finally, watch the control-plane layer. ai-dynamo and ONNX Runtime are both making bets on a future where operators mix engines, backends, and accelerators rather than standardizing on one.8 That may end up being the most important architectural shift of the year.
Major Releases
This is where version numbers and release details live.
vLLM shipped, a focused patch release centered on backend correctness and compatibility rather than a broad feature wave.16 The dominant theme was hardening: fixes for SM100 MLA defaults, Python compile-mocking behavior, and TensorRT-LLM MoE routing. The bigger story is that it landed in the middle of a much larger week of KV-cache quantization, executor redesign, and heterogeneous backend work.
SGLang released v0.5.10rc0, anchored by serving/runtime changes like piecewise CUDA graph defaults and elastic execution-provider support for partial failure tolerance.17 The release fits the week’s broader theme inside SGLang: disaggregated serving, low-precision kernels, and broader accelerator coverage across NVIDIA, AMD, NPU, MUSA, and MLX. The most impactful change was less the tag itself than the project’s continued push toward distributed, heterogeneous serving.
Ollama shipped after an earlier, with both releases focused on the MLX-powered Apple Silicon path.46 The dominant theme was stabilization: tokenizer compatibility, MLX cache behavior, and runtime correctness for newer model families. The most important change was making Apple-native local inference feel less experimental and more like a supported execution path.
Open WebUI released, a maintenance-oriented update focused on fixes and translation updates rather than major new capabilities.48 The week’s broader theme was frontend/runtime polish, including startup reliability, streaming efficiency, and config correctness. The most impactful change was reducing operational friction for users hitting install and startup issues.
ExecuTorch shipped, one of the week’s most consequential releases in edge inference.28 The dominant theme was real-time and portable on-device inference: Voxtral Realtime streaming, stronger Cortex-M support, backend improvements, and binary-size reductions. The most impactful change was the combination of streaming speech support and broader backend portability, which pushes ExecuTorch closer to production edge deployments.
sherpa-onnx released, continuing its pattern of broad cross-platform speech runtime expansion.29 The dominant theme was Qwen3-ASR rollout across many language bindings, plus source separation and runtime correctness fixes. The most impactful change was making a new ASR model family available across nearly every client surface at once.
FluidAudio shipped a rapid sequence of releases culminating in.30 Across the series, the dominant theme was ASR architecture cleanup plus new streaming and decoding capabilities, including new model support, custom-vocabulary improvements, and benchmark/runtime hardening. The most impactful change was the introduction of a cleaner streaming ASR architecture that makes the project more extensible as an on-device speech stack.
ROCm ATOM published, an important milestone because it marks the project’s first public ROCm-hosted release series.49 The dominant theme was benchmarking, validation, and initial polish after migration. The most impactful change was not a single kernel but the project’s move toward becoming a measurable, release-bearing part of AMD’s inference stack.
uzu-swift shipped, the week’s most substantial Apple-native SDK release in the supplied data.26 The dominant theme was SDK refresh and packaging for Swift/Metal consumers. The most impactful change was simply the scale of the update, which signals continued momentum for native Apple-platform inference tooling.
LiteRT-LM appeared in the supplied release data via, with a theme of Android and iOS performance, initialization, memory, and stability improvements.50 Even though it sat somewhat outside the repo-level summaries, it fits the week’s broader edge trend: mobile inference stacks are increasingly optimizing for deployability and runtime efficiency rather than just model support.