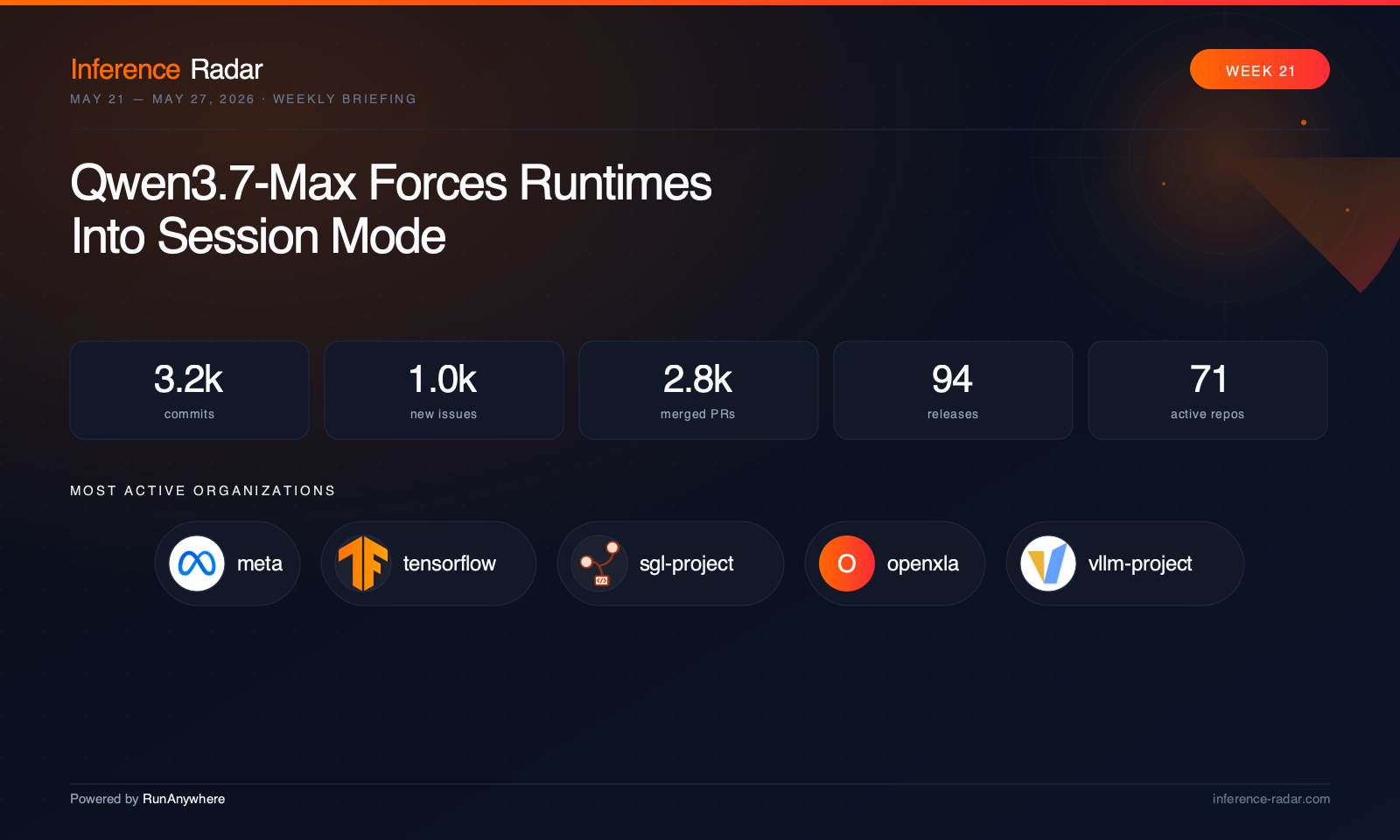

TL;DR
- Agentic serving got serious: SGLang, TensorRT-LLM, vLLM, ROCm, and ai-dynamo all pushed scheduler, KV-cache, speculative decoding, and tool-call reliability work for long-running inference sessions.1
- Local runtimes are becoming serving platforms: llama.cpp, Ollama, LocalAI, oMLX, Apple MLX, and vllm-mlx all moved closer to cloud-style features: MTP, OpenAI-compatible APIs, multimodal routing, and cache-aware execution.2
- Edge inference is now backend orchestration: LiteRT, ExecuTorch, ncnn, MNN, OpenVINO, XNNPACK, and Qualcomm AI Hub all worked on NPU, ARM, RISC-V, WebGPU, QNN, CoreML, and mobile deployment paths.3
- Memory is the new bottleneck: vLLM, TensorRT-LLM, ROCm AITER, OpenVINO, TileLang, and XNNPACK advanced FP8, INT4, NVFP4, KV-cache, and low-bit kernel work aimed at long-context cost reduction.4
- The release train favored hardening over hype: LocalAI, SGLang, TensorRT-LLM, ncnn, oMLX, osaurus, TileLang, DeepSpeed, and AITER all shipped focused updates around production reliability rather than broad new feature splash.5
This Week in Inference
The week’s only major outside-the-repo model signal was Alibaba’s Qwen3.7-Max, positioned around long-horizon agent execution, very large context, and extended tool-use loops rather than simple chat completion throughput (coverage).6 That framing matches what the open-source stack actually shipped: SGLang stabilized DeepSeek-serving paths, TensorRT-LLM expanded MTP and multimodal coverage, vLLM tightened runtime internals, and ai-dynamo kept pushing KV-aware distributed routing (SGLang, TensorRT-LLM, vLLM, ai-dynamo).1 The model race is increasingly a serving race: the hard part is no longer just loading the next checkpoint, but keeping sessions alive while tools, caches, images, audio, and long prompts stress every layer of the system.
The technical through-line was speculation plus compression plus scheduling. MTP and speculative decoding continued to spread from datacenter stacks into local runtimes, with llama.cpp, MLX-adjacent projects, vllm-mlx, oMLX, SGLang, TensorRT-LLM, and vLLM all showing variants of the same pattern: draft tokens are only useful if KV bookkeeping, cache rollback, mixed attention layers, and stream synchronization are correct (llama.cpp, vllm-mlx, oMLX, vLLM).2 Quantization work also moved below the headline “weights are smaller” story: ROCm, NVIDIA, OpenVINO, TileLang, XNNPACK, Intel Neural Compressor, and Google AI Edge all pushed low-bit kernels, FP8/INT4/NVFP4 paths, KV-cache defaults, or quantizer foundations that make memory traffic the strategic bottleneck (ROCm AITER, OpenVINO, TileLang, XNNPACK).11
Hardware news reinforced the same direction. Meta’s MTIA roadmap and NVIDIA partnership show hyperscalers taking a dual-track approach: custom inference silicon plus massive GPU procurement (MTIA coverage, partnership coverage).15 Meanwhile, edge frameworks were not waiting for one winning accelerator: LiteRT, ExecuTorch, ncnn, MNN, sherpa-onnx, Qualcomm AI Hub, and OpenVINO all advanced practical support for fragmented device targets (LiteRT, ExecuTorch, ncnn, sherpa-onnx).3 The market is converging on format pluralism and runtime translation, not a single blessed artifact.
Top Stories
SGLang turns DeepSeek, MLA, and Blackwell work into serving hardening
SGLang had one of the week’s most consequential serving updates, focused on DeepSeek stability, MLA prefill, context parallelism, HiCache behavior, Blackwell paths, and speculative-decoding correctness (SGLang).1 The project’s pattern is clear: it is becoming less “fast model server” and more “specialized runtime for difficult production workloads,” especially where MLA, disaggregated serving, cache hierarchy, and speculative paths interact. Its patch release also shows how much serving quality now depends on single-token decode correctness, allocator behavior, and mixed speculative paths rather than just headline benchmark throughput.20
NVIDIA TensorRT-LLM pushes MTP, multimodal, and sharding-IR forward
TensorRT-LLM continued its aggressive release-candidate cadence with support work across Qwen, Gemma, EXAONE, Laguna, DeepSeek, speculative decoding, FlashInfer, KV reuse, and sharding-IR canonicalization (TensorRT-LLM).7 The important signal is not any one model family; it is NVIDIA moving model-specific enablement into a faster backend pipeline where quantization, attention kernels, MTP, and disaggregated serving are treated as one integrated system. Edge users are already testing the limits of that stack on Jetson-class hardware, where Qwen, GDN, memory pressure, and OpenAI-compatible streaming surfaced as concrete pain points (TensorRT-Edge-LLM).21
ggml keeps local inference hardware-neutral
The ggml ecosystem had a broad week across llama.cpp and whisper.cpp, with backend work spanning Vulkan, WebGPU, CUDA, HIP, SYCL, Metal, OpenCL/Adreno, Hexagon/Snapdragon, ZenDNN, and shared ggml core synchronization (llama.cpp).2 That matters because local inference is no longer “CPU plus maybe CUDA”; users expect the same runtime to route across desktop GPUs, mobile GPUs, Apple Silicon, browser-adjacent backends, and embedded accelerators. whisper.cpp also absorbed core backend improvements while fixing JSON output and server upload behavior, showing that speech inference is benefiting from the same low-level infrastructure investment as LLM serving (whisper.cpp).22
vLLM hardens the serving substrate while Gaudi tracks upstream
vLLM spent the week on runtime plumbing: a Rust frontend path, DFlash allocation, speculative KV connector behavior, attention layout changes, Mooncake reset handling, scheduler liveness, quantization kernels, and multi-hardware fixes (vLLM).4 The Gaudi plugin closely followed upstream changes around Qwen hybrid GDN/attention behavior, MXFP4/GPT-OSS support, KV offload tests, stale-router MoE behavior, and CI security gates (vllm-gaudi).23 The takeaway is that vLLM’s center of gravity is shifting from OpenAI-compatible serving alone toward backend portability and fragile state-management correctness under speculative, hybrid, and distributed execution.
Google AI Edge and OpenVINO show edge inference becoming a full stack
Google’s LiteRT, LiteRT-LM, XNNPACK, Gallery, MediaPipe, and AI Edge Quantizer all moved this week, with work on WebGPU/JIT, NPU/dispatch, QNN, 4-bit ARM kernels, OpenAI-compatible local serving, token counting, multimodal chat, and GPTQ foundations (LiteRT).3 OpenVINO mirrored the same pressure from the other direction: GPU/CPU/NPU execution paths, 4-bit KV-cache defaults, speculative decoding, PagedAttention-style extensions, GenAI TTS, and image-generation samples all advanced together (OpenVINO, openvino.genai).12 Edge is now a systems problem: runtime, kernels, model packaging, local APIs, samples, profiling, and app UX all have to move in lockstep.
Deeper Dive
Everything below is for readers who want the full picture. Feel free to scroll.
Code Changes by Category
Cloud & Datacenter Serving
vLLM focused on serving internals, adding a Rust frontend option, improving speculative decoding and KV connector behavior, tightening attention layouts, and expanding quantization and hardware support across CUDA, ROCm, XPU, CPU, TPU, and Gaudi-adjacent workflows (vLLM).4 Its Gaudi plugin tracked upstream model and runtime changes closely, especially Qwen hybrid GDN/attention fixes, GPT-OSS MXFP4 tensor-parallel partitioning, penalty sampling device placement, and KV offload semantics (vllm-gaudi).23
SGLang pushed hard on DeepSeek, MLA, FlashMLA, context parallelism, Blackwell, HiCache, disaggregated serving, and speculative decoding, while also widening model support across Nemotron, Ling, Qwen-VL, Qwen-Omni, and diffusion/audio-serving paths (SGLang).1 NVIDIA TensorRT-LLM advanced Qwen MTP, Gemma multimodal, FlashInfer, EXAONE, DeepSeek, GDN, Mamba, KV cache manager work, and GB-class compatibility fixes (TensorRT-LLM).7
ai-dynamo had a production-readiness week around KV-router scheduling, queue-depth backpressure, overlap refresh, sticky-session routing, tool-call parsing, Kubernetes planner/profiler correctness, EFA/libfabric images, XPU/CPU vLLM builds, TensorRT-LLM backend bumps, and LMCache launch alignment (ai-dynamo).8 Ray advanced Ray Serve and Ray LLM with HAProxy/direct-ingress routing, direct streaming for DP/PD builders, controller health metrics, TPU defaults, and production data-path work in Ray Data (Ray).25
LMDeploy fixed concurrent tool-call streaming, OpenAI-compatible streaming usage chunks, allowed tool choice handling, FA3/KV-cache correctness, multimodal memory pressure, Intern-S1 key mapping, and Qwen evaluation configs (lmdeploy).26 Triton Inference Server fixed a production crash path for slow S3-backed model loading by ignoring SIGPIPE in the standalone server, tightened integer parsing in HTTP/SageMaker/Vertex paths, and prepared compatibility documentation for its latest platform refresh (Triton server).27
Local LLM Runtimes
llama.cpp continued its rapid build cadence with ggml core syncs, backend improvements across Vulkan/WebGPU/CUDA/SYCL/Metal/Hexagon/OpenCL, tokenizer and model support, GGUF API work, server fixes, tensor-parallel sizing, MTP/KV-cache fixes, and broad CI reshaping (llama.cpp).2 whisper.cpp absorbed the same ggml backend wave while fixing UTF-8 JSON behavior, multipart WAV uploads, release prep, and C API safety discussions (whisper.cpp).22
Ollama reverted an invasive MLX DFlash integration while preserving reusable draft-architecture detection, recurrent-state precision, and YaRN helpers, signaling a maintainer preference for smaller reusable runtime primitives over broad speculative-decoding rewrites (Ollama).28 LocalAI shipped a large routing and middleware push covering model routing, PII filtering, distributed-mode attribution, loaded-replica routing, multimodal backends, LTX video support, ASR fixes, and usage/admin UI improvements (LocalAI).5
llamafile repaired CPU performance regressions around MoE K-quant matmul, CPU flash attention, and Apple Silicon thread detection, with follow-up work already scoped against upstream llama.cpp deltas (llamafile).29 exo hardened distributed-runtime crash behavior, model-instance availability UX, and background daemon operation while users continued to report Thunderbolt/RDMA, tensor-parallel, and zombie-instance failure modes (exo).30
Apple Silicon & MLX Ecosystem
Apple’s MLX core prioritized correctness over silent failure, adding shape-product overflow checks, Array API copy semantics, and safer handling of unsupported tensor-scale NVFP4 paths in Metal quantized matmul (MLX).31 Core ML Tools fixed conversion edge cases around ConvTranspose, randint, einsum ellipsis lowering, palettization, and scalar-like reshape/view handling (coremltools).32
MLX Swift and MLX Swift LM moved quickly on Gemma, Qwen VL, Qwen, LoRA/PEFT loading, VLM fixes, benchmarking helpers, tool-call behavior, gated-delta handling, and eval-state cleanup for MTP foundations (mlx-swift-lm).33 oMLX moved toward a native Swift macOS app while aggressively hardening memory guard tiers, adaptive prefill throttling, store-cache cleanup, VLM/MTP loading, per-engine stream isolation, and API compatibility (oMLX).10
Blaizzy’s MLX ecosystem expanded audio, VLM, and image-generation coverage: mlx-audio added Mega-ASR, VAD, TTS work, and realtime server behavior, while mlx-vlm added PrismML Bonsai image generation, DeepSeek MTP support, OpenAI-compatible server polish, and model-loading fixes (mlx-audio, mlx-vlm).34 vllm-mlx shipped an Apple-silicon serving release candidate focused on Gemma MTP, cache/streaming fixes, benchmark refactors, Python-overhead reduction, and tool-call/reasoning behavior (vllm-mlx).9
Mobile & Edge Frameworks
ExecuTorch pushed Android/Kotlin APIs, LLM/ASR runners, CoreML compute-plan inspection, Arm/Cortex-M, Qualcomm QNN, NXP Neutron, CUDA, WebGPU, RISC-V, and portable runtime work, reinforcing Meta’s edge stack as a broad deployment substrate rather than a single backend (ExecuTorch).17 Google LiteRT advanced Tensor API cleanup, WebGPU/JIT demos, NPU dispatch, QNN support, ARM 4-bit kernels, tooling fixes, and LiteRT-LM’s OpenAI-compatible local serving path (LiteRT, LiteRT-LM).3
ncnn shipped a release with HarmonyOS packaging, RISC-V convolution refactors, ARM SIMD activations, MIPS/LoongArch cleanup, 4D Mat expansion, UnaryOp coverage, PNNX fixes, Android Hardware Buffer zero-copy docs, and broad packaging updates (ncnn).18 Alibaba MNN focused on converter/runtime correctness across ONNX Einsum and Resize, Vulkan/OpenCL attention paths, PyMNN packaging, Android/local CI, and Blackwell CUDA support (MNN).37
Cactus advanced multimodal chunked prefill, Parakeet/Whisper speech conversion, CQ4 LM-head performance, Android load-aware scheduling, and Flutter privacy/offline-mode discussions (Cactus).38 sherpa-onnx fixed a heap-buffer-overflow in TopkIndex handling and expanded Python API docs while users pressed on VAD longevity, mobile TTS, NPU support, and confidence-score APIs (sherpa-onnx).19
Compilers, Runtimes & Graph Engines
TVM and tvm-ffi moved structural equality/hash infrastructure into the standalone FFI layer, expanded Relax frontend coverage for TFLite and ONNX, split runtime backends into DSOs, and hardened RPC/security edges (TVM, tvm-ffi).39 OpenXLA had a high-throughput week around GPU command buffers, PJRT cross-host transfer, autotuning, Triton/cudnn/ROCm/oneAPI portability, C API evolution, and robustness fixes (XLA).41
Triton language focused on MX-scaled and swizzled matmul correctness, persistent TF32 shared-memory accounting, AMD backend options, sanitizer behavior, TMEM alignment, tl.dot semantics, and verifier cleanup (Triton).42 TileLang shipped a broad backend/compiler release covering CUDA, ROCm/HIP, Metal, CPU backend specialization, FP4/TF32/TMA/WGMMA work, PyPI publishing, Windows packaging, and pipeline correctness (TileLang).13
ONNX and ONNX Runtime advanced LLM attention semantics, sliding-window attention design, GroupQueryAttention, quantized KV cache, QMoE CUDA, WebGPU LinearAttention, RISC-V RVV LLM ops, CUDA numerical correctness, CoreML execution provider coverage, and spec/reference fixes (ONNX, ONNX Runtime).43 AMDMIGraphX added static build support, external HIP stream contexts, MI350 MLIR attention defaults, environment-driven autotuning, compile-time measurement, and pass-pipeline refactors (AMDMIGraphX).45
Models, Quantization & Optimization
Hugging Face Transformers and Diffusers expanded multimodal/model coverage with AnyFlow video diffusion, audio-language base classes, GLM vision processor support, RF-DETR pipeline work, XPU FlashAttention paths, Gemma stability, distributed training fixes, and security hardening around saved paths (Transformers, Diffusers).46 Candle focused on CUDA graph readiness, per-thread streams, quantized pointer guarding, H2D metadata caching, FlashAttention fixes, and CUDA compatibility (Candle).48
Intel Neural Compressor fixed JAX/Keras quantization loading and incomplete calibration behavior, updated LLM quantization examples for AISBench and vLLM CUDA compatibility, and continued Qwen/DeepSeek AutoRound maintenance (Neural Compressor).49 ROCm AITER and ATOM moved in lockstep on DeepSeek V3/V4, MLA, fp8 KV cache, MTP/speculative decoding, DP serving, blockscale GEMM, MoE, gfx950, and SGLang/vLLM integration paths (AITER, ATOM).11
Google AI Edge Quantizer added GPTQ foundations and calibrator tests, while XNNPACK refreshed SIMD transcendental math, quantization, compiler/subgraph behavior, split-K, static-shape handling, and LiteRT ATS coverage (AI Edge Quantizer, XNNPACK).14 try-mirai’s lalamo and uzu advanced compression, Lloyd-Max/codebook work, unified quantized GEMM, sparse-buffer KV-cache plumbing, mixed precision, and Linux CPU portability (lalamo, uzu).52
Other Notable Changes
LiteLLM had a high-velocity provider and enterprise-proxy week: Gemini/Vertex Live tool calling, OCI GenAI, Microsoft Purview DLP guardrails, Galileo telemetry, realtime reliability, proxy admin workflows, MCP, SSO, team/key management, and Docker signature documentation all moved (LiteLLM).54 osaurus shipped a rapid desktop-agent release train focused on vMLX proof gates, provider compatibility, privacy filtering, plugin security, chat UX, model-library reliability, and /v1/completions for autocomplete workflows (osaurus).55
Open WebUI had little merged code but high community pressure around knowledge search, migration failures, SSO redirect behavior, OpenTerminal access semantics, tests policy, and contribution governance (Open WebUI).56 FastChat, text-generation-webui, DeepSeek-V3, and UbiquitousLearning mllm were mostly issue-driven this week, with reports around Arena account failures, image-only vision prompts, MTP GGUF backend gaps, DeepSeek prompt-anchor oddities, and Qualcomm QNN compilation failures (FastChat, text-generation-webui, DeepSeek-V3, mllm).57
Community Pulse
The highest-energy repos were the serving engines and runtime foundations: vLLM, SGLang, TensorRT-LLM, ai-dynamo, ggml, TensorFlow, OpenXLA, LiteRT/XNNPACK, and ROCm all showed heavy PR throughput around scheduler correctness, backend coverage, and low-level kernels (vLLM, SGLang, TensorRT-LLM, ggml).1 User pressure clustered around long-context memory, OpenAI-compatible API parity, tool-call streaming, hardware-specific failures, and model-family churn rather than “how do I run a model” basics.
Local and desktop apps also saw major attention: Ollama, LocalAI, oMLX, Open WebUI, osaurus, and text-generation-webui all dealt with the reality that local inference users now expect agent integrations, tool calls, model libraries, privacy controls, and polished desktop workflows (Ollama, LocalAI, oMLX, osaurus).5 Edge communities were more hardware-specific: Qualcomm QNN, Jetson, Android, RISC-V, Apple Silicon, NPU, WebGPU, and ARM paths all produced actionable reports and fixes (Qualcomm AI Hub Models, TensorRT-Edge-LLM, ncnn).18
Community Debates
Ollama drew a clear line between PagedAttention and block-based KV management. A community PR proposed a vLLM-style PagedAttention KV cache, but maintainers closed it after arguing the implementation was not actually PagedAttention and was closer to block-managed KV caching (discussion).62 A separate continuous-batching proposal was closed because maintainers said Ollama already supports the concept, showing that performance PRs need to match the project’s existing scheduler model rather than reintroduce concepts under new names (discussion).63
vLLM’s maintainers pushed for common abstractions over isolated kernel wins. INT2/INT4 KV-cache quantization work was considered promising but closed because reviewers wanted a multi-backend KV quantization contract rather than a Triton-only interface (discussion).64 Sonic MoE also showed promising H100 microbenchmarks but was closed after maintainers asked for deployment guidance, E2E performance data, profiler evidence, and alignment with the broader MoE kernel-selection refactor (discussion).65
SGLang debated cache correctness versus refactor size. A HiCache/SWA proposal argued that prefill/decode cache assumptions break when hierarchical cache and disaggregated serving interact, but maintainers closed it as too broad and redirected toward a narrower path (discussion).66 A scheduler proposal to retract on transient prefill KV OOM was rejected because maintainers expect the existing prefill budget machinery to reserve the needed capacity (discussion).67
Open WebUI’s test and contribution policy remained contentious. Multiple PRs and discussions were blocked or redirected over CLA status, target branches, title/template rules, branding assets, and a maintainer preference not to accept community test-only PRs into the main repo (discussion).68 The OpenTerminal access-control discussion also exposed a product philosophy gap: users wanted group-based containment, while maintainers argued the terminal account should be treated as the user itself (discussion).69
Triton language rejected sub-byte local allocation in favor of explicit IR. A PR tried to make i1 local_alloc lowering work, but maintainers argued sub-byte allocation was the wrong abstraction and followed with a ban on the pattern (discussion).70 The outcome is a useful compiler-community signal: correctness and IR clarity are winning over permissive lowering tricks in fast-moving backend code.
TileLang’s shared-memory work showed the cost of aggressive compiler reuse. Shared-memory reuse landed and was then reverted after hidden MMA descriptor dependencies made the optimization unsafe, while safer aliases and disable flags were preserved (revert path).71 The debate fits the week’s broader theme: memory optimization is the prize, but only if the compiler can prove it is not corrupting execution state.
Worth Watching
- KV cache compression and hierarchy are becoming product features, not research extras, as vLLM, SGLang, TensorRT-LLM, ROCm, OpenVINO, LocalAI, and ai-dynamo all work around KV reuse, offload, hierarchy, or scheduler interaction (vLLM, SGLang, ai-dynamo).1
- MTP and speculative decoding are crossing into local UX, with llama.cpp, MLX-adjacent stacks, oMLX, vllm-mlx, TensorRT-LLM, SGLang, and vLLM all treating draft execution as a mainstream runtime path (llama.cpp, oMLX, vllm-mlx).2
- OpenAI-compatible local servers are spreading to the edge, with LiteRT-LM, LocalAI, Cactus, osaurus, vllm-mlx, mlx-vlm, and oMLX all converging on familiar API surfaces for desktop and device-local apps (LiteRT-LM, Cactus, osaurus).36
- Backend abstraction pressure is rising, especially around AMD, XPU, NPU, QNN, RISC-V, WebGPU, Apple Silicon, and Jetson paths where “CUDA-first” assumptions keep surfacing as bugs (ROCm, ncnn, LiteRT).3
- Security and CI policy are becoming inference-infra differentiators, visible in TensorFlow/tflite-micro hardening, LiteLLM Docker signature docs, LocalAI signed backend images, Open WebUI contribution gates, and Triton’s production crash/security follow-ups (TensorFlow, LiteLLM, LocalAI, Triton server).5
Major Releases
This is the canonical release reference for the week.
BerriAI shipped a rapid LiteLLM release train across v1.84.1, v1.85.1, v1.86.0, v1.86.1, v1.86.2, v1.87.0-rc.1, v1.87.0-rc.2, and related patch tags, with the dominant theme being Docker image signature verification, non-root image repair, and release hygiene. The code activity underneath was broader than the release notes: Gemini/Vertex Live tool calling, OCI GenAI support, guardrails, telemetry, proxy admin workflows, and MCP/SSO hardening all moved. Representative release.73
DeepSpeed released v0.19.1, a maintenance-focused update around CI reliability, PyTorch compatibility, ZeRO-3 torch.func support, flash-attn API handling, CUDA architecture handling, and optimizer memory use for frozen-parameter fine-tuning. The most impactful runtime change was reducing FP16 optimizer buffer pressure for LoRA/PEFT-style workloads with frozen weights..74
ggml shipped an unusually dense llama.cpp build train from b9255 through b9371, with shared ggml syncs, backend acceleration, Vulkan/WebGPU/CUDA/SYCL/Metal/Hexagon/OpenCL improvements, server fixes, GGUF API work, and tokenizer/model additions. whisper.cpp also moved to v1.8.5 in-repo, reflecting the same shared-core synchronization and user-facing fixes around JSON and uploads. Latest llama.cpp release in window.75
Google AI Edge published AI Edge Gallery 1.0.15 and LiteRT-CLI v0.1.1. Gallery’s release focused on agent-skill prompt behavior when MCP tools are present or absent, while the broader org activity centered on LiteRT runtime APIs, WebGPU/JIT, NPU/QNN support, XNNPACK kernels, LiteRT-LM OpenAI-compatible serving, and GPTQ quantizer foundations. Gallery release notes.76
jundot shipped oMLX v0.3.9, v0.3.10, v0.3.11, and v0.3.12, a fast stabilization train around native macOS app direction, MTP support, memory-guard tiers, adaptive prefill throttling, store-cache cleanup, and long-context OOM behavior on Apple Silicon. The late-week v0.3.12 patch retuned memory ceilings after users found the previous guard too conservative. Latest release.77
mudler shipped LocalAI v4.3.0, v4.3.1, and v4.3.2. The release line focused on signed backend OCI images, gallery verification, distributed-mode optimizations, default llama.cpp prompt cache, per-API-key usage attribution, middleware/routing, backend updates, and dependency patches..78
NVIDIA shipped TensorRT-LLM v1.3.0rc15 and v1.3.0rc16. The release candidates expanded Gemma4 multimodal, Qwen3.5 MTP, Qwen3.6 FP8, EXAONE/Laguna, Kimi, GPT-OSS, Nemotron, DeepSeek, sharding-IR canonicalization, VisualGenArgs, FlashInfer, and hybrid/disaggregated serving paths. Latest release notes.79
ROCm released AITER v0.1.14, focused on DSv4 fusions, MiniMax fused qknorm/allreduce prefill improvements, and a grid-strided-loop fix removing a token cap. The broader ROCm week also saw ATOM and AMDMIGraphX advance DeepSeek V3/V4, MLA, fp8 KV cache, speculative decoding, DP serving, MI350 attention defaults, and external HIP stream contexts..80
SGLang released v0.5.12.post1, a stability patch dominated by DeepSeek V4 fixes, B200/B300 decode correctness, deep_gemm scale packing, and EAGLE/MTP disaggregated decode allocator behavior. The release capped a much larger week of MLA, context-parallel, HiCache, Blackwell, multimodal, and speculative-decoding work..20
Tencent shipped ncnn 20260526, with 42 assets across Android, HarmonyOS, iOS, macOS, Linux, Windows, WebAssembly, watchOS, tvOS, and visionOS. The release reflected a portability-heavy week: RISC-V convolution refactors, ARM SIMD activations, 4D Mat work, UnaryOp expansion, PNNX fixes, pybind updates, and Android zero-copy documentation..81
TileLang and vllm-mlx both shipped under the miscellaneous grouping. TileLang v0.1.10 focused on PyPI publishing, Windows/TVM packaging, backend-specific compiler pipelines, Metal GEMM, CUDA/ROCm/HIP work, FP4/TF32/TMA/WGMMA fixes, and autotuning cleanup; vllm-mlx 0.4.0rc1 focused on Gemma 4 MTP, streaming/cache fixes, benchmark refactors, and Apple-silicon serving polish. TileLang release notes.82
osaurus-ai shipped 0.18.33 through 0.19.0, a fast desktop-agent release train around vMLX proof gates, provider compatibility, privacy filtering, plugin containment, XLSX/document parsing, global proxy wiring, chat UX, model-library fixes, and /v1/completions support for autocomplete workflows. The most significant release was 0.19.0, which consolidated FIM autocomplete, network exposure persistence, custom base URLs, privacy filtering, and vMLX hardening..83
try-mirai shipped lalamo v0.11.0, v0.11.1, and v0.11.2. The release line carried parser fixes, remote-registry changes, a major quantization/compression merge, stable residual and DeltaNet precision fixes, dependency repair, and agent-directory cleanup, while uzu continued runtime work on unified quantized GEMM and sparse-buffer KV plumbing without a release. Latest release.84